
Photo from Wikimedia Commons
{kind=link}
Do you have large volumes of data that need tens of seconds to minutes to process? Introducing BigQuery. Wait, this is not an advert. This is a part of my l̶a̶z̶y̶ documentation when working with BigQuery.
⚠️WARNING: Wall of Text Below
My writing below is more complex and longer to read than the actual code itself, especially if we’re talking the same language. Skip to the bottom to see the code for yourself. The writing may only make sense to me. You have been warned.
The Problem
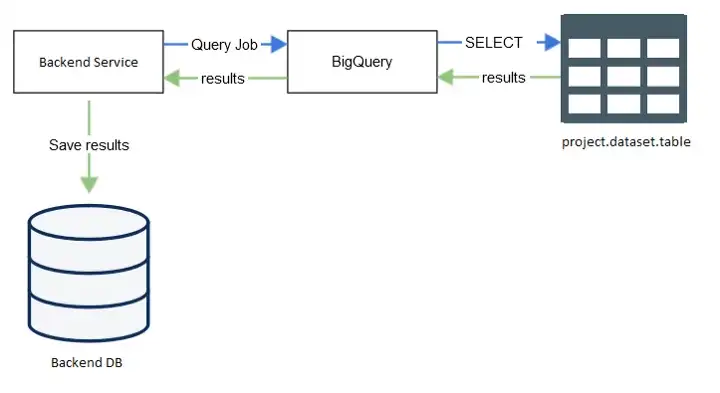
Table icon from icons-for-free.com; DB icon from pixy.org
That’s the usual flow (simplified) to fetch & save small result sets from BigQuery. First, backend creates a query job on the BigQuery, and then BigQuery execute the job which is usually just an SQL SELECT query, and then the result is passed back to our backend service, and finally it’s saved to a permanent / temporary table for later viewing. BUT the last step is not as easy as it seems. Google’s BigQuery Client Library doesn’t give us any library to convert the query result to a POJO or a business entity easily.
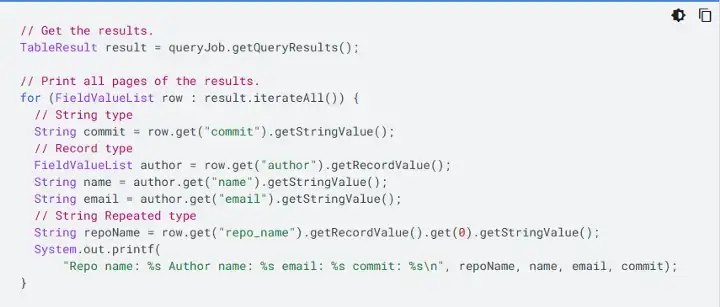
Taken from Google’s BigQuery Quickstart for Java (June, 2022)
Reading the Google’s BigQuery Quickstart raised my eyebrows, my searches raised them higher. I had to map the column to the correct data type (and then to the POJO property) one-by-one. My laziness immediately kicked in and forced me to do sanity check (literally) on my future-self if I keep doing it… *ugh* nope nope. This writing will try to introduce an idea to skip that verbose work once for all. All snippets will be in Java.
Requirements
- Authenticated & authorized access to use BigQuery API
- Google’s BigQuery Client Library or Spring Cloud GCP starter (if you’re using Spring)
- Any reactive stream library — here I use RxJava which is slowly dying
You can also use Project Reactor or Kotlin’s Coroutine and Flow. - A library to deserialize java.util.Map into POJO — here I use FasterXML’s Jackson, specifically: jackson-core, jackson-annotations, jackson-databind, jackson-datatype-jsr310
The (Lazy) Idea
To differentiate between “BigQuery object” (from the library) and “BigQuery platform”, I’ll refer the “BigQuery platform” as BQ from now on.
We need a helper class that will be responsible to fetch BQ data based on an SQL string, and returned the reactive stream that will emit the result row-by-row where each row is an object from any POJO class that’s specified by the caller. To keep it simple, I’ll name the class BigQueryClient.
This class will only have 2 instance fields, BigQuery and ObjectMapper.
- For the constructor, our simple BQ client will accept a
BigQueryobject (from the Google library). - For deserializing the response later, we need to configure the
ObjectMapperto suit our needs (Line 8–11). In this case, we’ll ignore unknown properties and change the property naming strategy to snake case. Why to snake case? Because column naming in BQ (which is an SQL data warehouse) usually uses snake_case. By changing the naming, the mapper will be able to recognize & map the fields of each row (from the BQ library result) to standard POJO properties in camelCase. - Next is a public method to fetch the BQ data (Line 14–17).
We made it generic so it can be used for mapping any POJO class.
The method accepts an SQL query string that’ll be executed in the BQ, and a Class object to define the POJO class of the objects that’ll be emitted by the returned Observable (reactive stream).
First we will execute the SQL string lazily by wrapping it in anObservable(Observable.fromCallable(..)). After the query result is successfully returned, it’ll then be transformed to a new reactive stream that emit individual rows (flatMap(….)).
Is the code simpler & easier to understand than my description above? If yes, the code is on the right path then 🙃.
Next is implementing the helper methods used by the public method:
query(String)
This is a standard code adapted from Google BQ Quickstart snippet. To run a query in the BQ, we need to create a query job using the BQ library then get the results. The steps are:
- create a new job configuration with the provided SQL string (Line 2).
- create the job using a randomly generated id (Line 4–9).
- wait for the query job to complete (Line 11).
- throw runtime exception on error (Line 13–17).
- finally get the query results splitted in pages, each has 100 rows (Line 19).
And that will give us a TableResult object.
readValues(TableResult, Class)
This helper will read & convert the result row-by-row to the specified value type.
- To get the specific field value from a row, we need to get it by the field name. So, we get all the field names first using the BQ library methods (Line 4, detail at Line 9–14). Nothing fancy, we’re just using standard BQ library methods.
- Next we create an observable from all iterable rows in the
TableResult(Line 5). - Next is where teh magic happens (Line 6).
Here we don’t need to map property name, value, and data type 1-by-1 to a POJO, we just let theObjectMapperdo the hard work. We only need to give theObjectMappera map of field value by field name (that’s the column_name), and the value type of the resulting POJO. And voila, each row will be mapped to the POJO.
This allow us to construct any kind of POJO with the vast Jackson deserialization features.
Example
If we want to fetch monthly report from a specific project and dataset, and then save the result to the backend service db, for example we may do this:
Next time we need to query another table, we only need to create the POJO(s) as the mapping. Easy-peasy, while still providing type-safety.
That’s all Folks!
This is surely not the best code for fetching & mapping BQ data to POJOs performance-wise (use bulk data export or BQ Storage Read API for fetching millions of data faster). As the title suggest, this is only a simple client that’s written to introduce an idea to fetch and especially map the BQ data easily. Feel free to extend the idea to suit your needs.
The full snippet can be found on my Github’s gist.