
Photo by Nathan Anderson on Unsplash
To be self-contained, this article repeats many points from my previous article to do query routing with Spring JPA.
First thing first, before you expect anything from this article, this is NOT a general guide to route queries with any ORMs and/or DBMS. This article is focused to:
- Spring Boot 3
- Spring R2DBC 3 (version that starts to support connection failover)
- SQL Database with R2DBC driver, specifically PostgreSQL
If you use other SQL database, you can check the list of supported drivers.
In short, this article is for fully reactive Spring Boot WebFlux app which uses SQL database.
If you’re using Spring JPA, check my previous article to do query routing with Spring JPA.
This article assumes we follow a standard single primary-replication scheme, which should fit most applications that read a lot more data than they write. There are several advantages to separating write and read requests to different database server(s).
First, it improves database performance. Your writes won’t be impacted by your reads. We can also tune each database for its specific purpose.
Second, it improves scalability, easier to scale each database independently. This is particularly useful in situations where the application experiences high read traffic, but low write traffic, or vice versa. Although scaling write database can only be done vertically, scaling read database can be done horizontally by adding more replicas.
Moreover, separate read and write databases can improve fault tolerance.
In the event of write database outage, database system can promote any of the read databases to be the next write database while we restoring the original write database. This can minimize downtime and ensure that the application remains accessible to users.
In the case of read database failure, all read requests can be routed to write database while we restoring the read databases.
The idea
Suppose we have 2 database servers: one is primary - the read-write database, the other is secondary - the read-only database, a replica of the primary.
Often, secondary is used only by viewer/reporting app, and also as a failover database when the primary is unavailable, while primary is highly utilized from high reads and writes from the main app.
If the secondary has low utilization, why not using it specifically for processing read-only requests, so primary can focus to handle only read-write requests.
To utilize both servers effectively, we can route every query to either primary or secondary. The idea is simple:
- All read-write queries should be routed to primary database
- All read-only queries should be routed to secondary database
- When secondary fails, all read-only queries should be routed to primary database
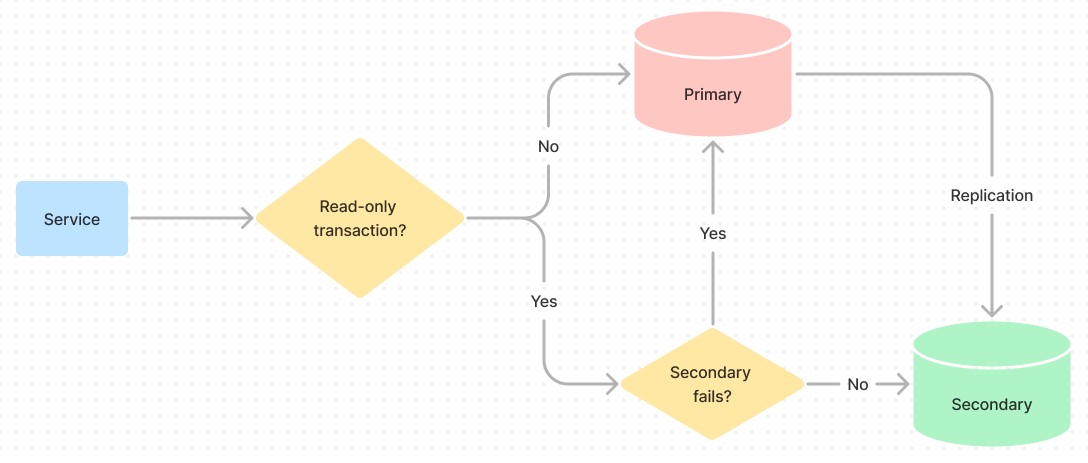
Query routing plan
The implementation
Following the diagram, the routing logic should be done at app/service level. To do the routing, we need to have at least two connection pools: one for read-write, one for read-only. There’s a Spring Boot doc to set up two datasources which could be adapted to fit our R2DBC use-case. With r2dbc-postgresql, for example:
This is just a sample configuration. DO NOT follow the values blindly. See “Suggestions” section below.
The *.url property has 2 important points:
- Both instances are registered as potential hosts of read-write and read-only database. This is important if you want to set up connection fail-over.
- For read-write the driver must only use primary database, while for read-only the driver should prioritize secondary database over primary database.
This simple connection fail-over is useful to create a high availability database installation.
- In case of failure on the primary database, to have minimal downtime, the secondary database could be promoted to be a primary so no further write transaction will be lost.
- In case of failure on the secondary database, because there’s no other secondary, the driver will automatically uses the primary database as the next read-only database.
- The driver will try once to connect to each of them in order until the connection succeeds. If none succeeds a normal connection exception is thrown.
The configuration code is simple, only consists of 3 new classes:
1. Database Type
A simple enum that will be used for routing keys. We will need to access the enum from other classes later.
2. Routing Connection Factory
With Spring JPA, transaction flags are available before obtaining a connection from a connection factory, so we could determine the target connection by evaluating the read-only flag.
With Spring R2DBC, this is not the case. Transaction definition flags are propagated to the transaction context after obtaining a connection from a connection factory, so the read-only flag can’t be evaluated at the time of connection retrieval.
Our only chance to implement routing mechanism is by attaching some contextual info to the reactive stream, using only @Transactional annotation is not enough.
The transaction routing logic is quite straightforward.
To get the target connection factory, AbstractRoutingConnectionFactory will determine current lookup key first which we can simply implement by checking if there’s a specific DatabaseType information in the current context.
If none, defaults to read-only database.
3. Database Configuration
This is a bit complicated. I adapted some code to create a ConnectionFactory from the original R2dbcAutoConfiguration and ConnectionFactoryConfigurations.
If you have a less code and/or a more concise way to do this, please drop me a message.
Beside that, we are just configuring a routing connection factory from previous step that will route the query to either the read-write database or the read-only database.
Hey, it’s not working!
Of course not!
Just like I said at configuration #2 above, we need to add a routing information to the context i.e. DatabaseType that’s appropriate for current transaction.
For read-only transaction, because the default is DatabaseType.READ_ONLY, we don’t need to add it to the context. But for read-write transaction, we need to add it to the context manually.
That’s it. This will make the RoutingConnectionFactory able to determine the correct connection factory.
Suggestions
Don’t mix transaction routing in a single request session
The reason is it may cause race condition in a tight cycle of write and read. From my experience, there’s a noticeable database replication delay - even though it’s in milliseconds, which may cause data inconsistencies if you read row X in a read-only transaction right after writing row X on a read-write transaction. This write-read cycle is usually common during bulk processing or parallel processing.
In a single request session, I recommend to either route to only read-only database (for example, only for GET APIs), or route to only read-write database. If you use both, make sure there is only one routing information to the read-write database in the stream pipeline context so all statements will always run on the primary database.
Setting the default database type for your use-case
This is for development and maintenance efficiency. In this article, I use read-only database as the default. But your service may have a lot more write APIs than read. If you change the default connection to read-write database instead, you will save extra effort because you only need to maintain and write the context on fewer APIs.
Set R2DBC pool properties related to timeout
Most default to no timeout, which depending on your use-cases, may cause bad performance issues.
For example, your database server or infrastructure may have a connection time limit for every connection established from a client.
If this is the case, then you should configure maxLifeTime to several time shorter than your database or infrastructure connection time limit, so there will be no stale connections in the pool.
See the github doc for the available properties.